Title: Whose Opinions Do Language Models Reflect?
Abstract: Language models (LMs) are increasingly being used in open-ended contexts, where the opinions they reflect in response to subjective queries can have a profound impact, both on user satisfaction, and shaping the views of society at large. We put forth a quantitative framework to investigate the opinions reflected by LMs – by leveraging high-quality public opinion polls. Using this framework, we create OpinionQA, a dataset for evaluating the alignment of LM opinions with those of 60 US demographic groups over topics ranging from abortion to automation. Across topics, we find substantial misalignment between the views reflected by current LMs and those of US demographic groups: on par with the DemocratRepublican divide on climate change. Notably, this misalignment persists even after explicitly steering the LMs towards particular groups. Our analysis not only confirms prior observations about the left-leaning tendencies of some human feedback-tuned LMs, but also surfaces groups whose opinions are poorly reflected by current LMs (e.g., 65+ and widowed individuals).
Bibliography: Santurkar, Shibani, Esin Durmus, Faisal Ladhak, Cinoo Lee, Percy Liang, and Tatsunori Hashimoto. “Whose Opinions Do Language Models Reflect?,” n.d.
Notes
- a different approach to “evaluation”: instead of queries that have “correct” responses, we evaluate the opinion encoded from the model’s response, and compare that to those of humans.
- Pew Research’s American Trends Panels survey turned into a dataset, 1498 Qs spanning science, politics, and personal relationships
- Findings:
- there is substantial misalignment between the opinions reflected in current LMs and that of the general US populace
- HF amplifies misalignment by being modal biased (liberal)
- i.e., just express the dominant viewpoint of certain groups
-
99% approval rating for Joe Biden
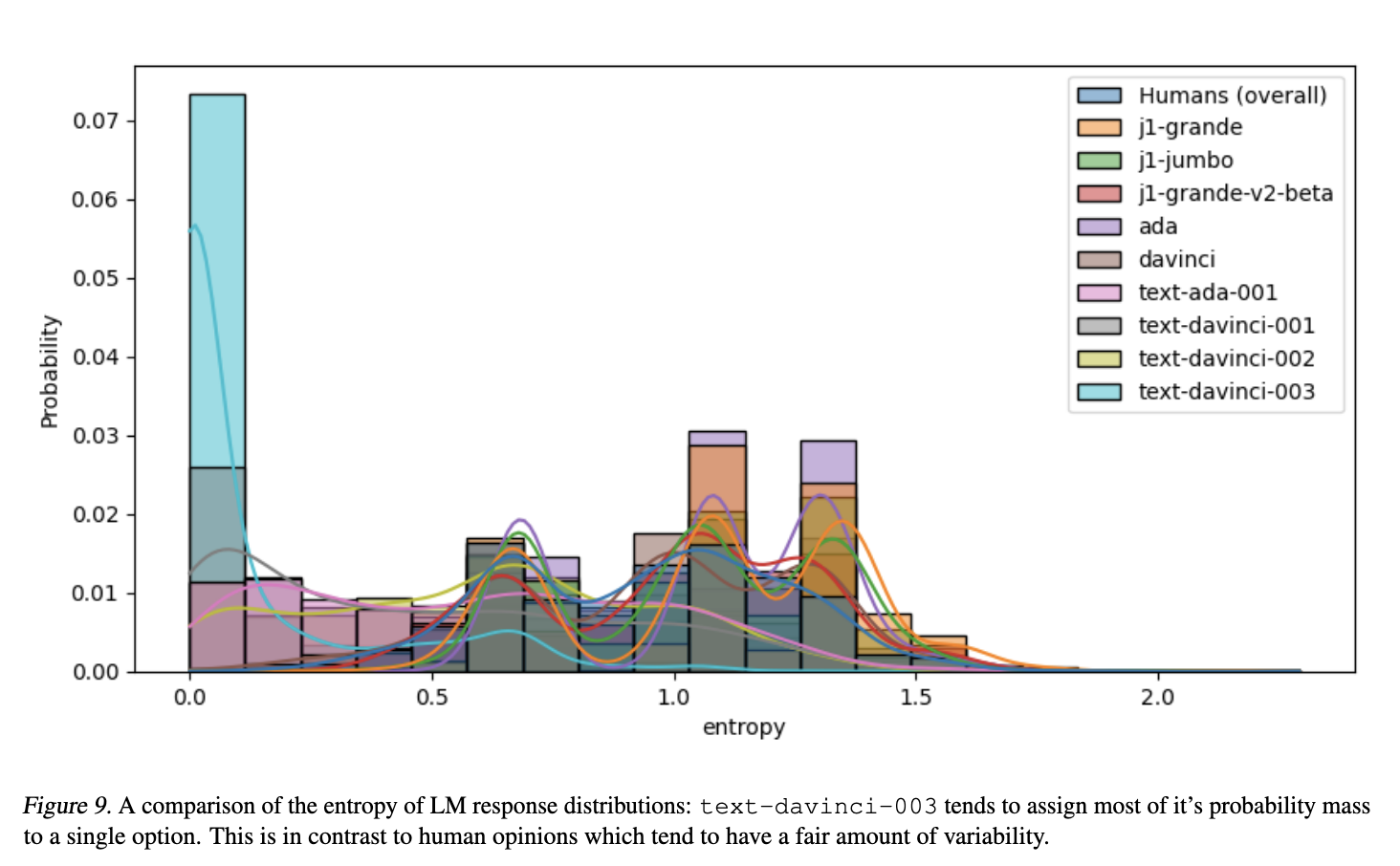
- none of representativeness problems are resolved by prompt steering
- models aren’t very consistent in their views
- e.g., liberal model expressing conservative views on topics such as religion
- Methods:
- multiple choice surveys provide some deterministic behavior from models
- next-token log probabilities are taken from LM and normalized to obtain models’ opinion distribution
- this distribution is compared to a human’s, based on their responses to the Pew Research survey
- Interesting details:
- omitted refusals, since they are not ordinal, and cannot be used in distribution comparison
- look into what the models refused to… but generally, paper mentioned less than 1-2% refusal rating, even with HF models
- this work considers human alignment as an inherently subjective quantity that depends on who it is measured against, rather than it being a single quantity that can be improved
- similar to recent calls for “pluralistic alignment”
- higher alignment may not be so desirable with this definition, e.g., matching racist views… or even possible, e.g., aligning with both Democrats and Republicans on abortion
- survey questions were multiple choice, remains as a question if same behavior will scale to open-ended text generation setting
- future work with non US and WEIRD society opinions, and whether opinion alignment measured through multiple choice will be reflected in the downstream sue casees of LMs
- omitted refusals, since they are not ordinal, and cannot be used in distribution comparison
- My thoughts:
- LMs are opinionated by nature. And well-intentioned people understand what perspectives they are missing, either through their own identities, as well as the identities of the social environments they are in.
- What if we could steer LMs politically? Would people think that they gained a better understanding of someone through the LM’s representation of them?
- Contributions:
- Extension from the Opinions paper that found none of the aforementioned representativeness problems are resolved by steering.
- could see how modern models do with the replicated study, and
- how modern methods of steering (ablation and others) perform
- Exploring the opinion alignment measurements in downstream use cases of LMs
- Extension from the Opinions paper that found none of the aforementioned representativeness problems are resolved by steering.
- Could the survey data from Pew be used as representatives of population?
- Can we collect the chat data from conversations that people have with relative representatives?
- Would the chat data be a dataset contribution of “political debates” or something?