Metadata
Abstract: Recent advancements in general-purpose AI have highlighted the importance of guiding AI systems towards the intended goals, ethical principles, and values of individuals and groups, a concept broadly recognized as alignment. However, the lack of clarified definitions and scopes of human-AI alignment poses a significant obstacle, hampering collaborative efforts across research domains to achieve this alignment. In particular, ML- and philosophy-oriented alignment research often views AI alignment as a static, unidirectional process (i.e., aiming to ensure that AI systems’ objectives match humans) rather than an ongoing, mutual alignment problem. This perspective largely neglects the long-term interaction and dynamic changes of alignment. To understand these gaps, we introduce a systematic review of over 400 papers published between 2019 and January 2024, spanning multiple domains such as Human-Computer Interaction (HCI), Natural Language Processing (NLP), Machine Learning (ML). We characterize, define and scope human-AI alignment. From this, we present a conceptual framework of “Bidirectional Human-AI Alignment” to organize the literature from a human-centered perspective. This framework encompasses both 1) conventional studies of aligning AI to humans that ensures AI produces the intended outcomes determined by humans, and 2) a proposed concept of aligning humans to AI, which aims to help individuals and society adjust to AI advancements both cognitively and behaviorally. Additionally, we articulate the key findings derived from literature analysis, including literature gaps and trends, human values, and interaction techniques. To pave the way for future studies, we envision three key challenges and give recommendations for future research.
Bibliography: Shen, Hua, Tiffany Knearem, Reshmi Ghosh, Kenan Alkiek, Kundan Krishna, Yachuan Liu, Ziqiao Ma, et al. 2024. “Towards Bidirectional Human-AI Alignment: A Systematic Review for Clarifications, Framework, and Future Directions.” arXiv. https://doi.org/10.48550/arXiv.2406.09264.
Notes
AI alignment can be broadly defined as: ensuring an AI produces the intended outcomes without additional undesirable side effects.
This definition is quite broad. To understand AI alignment further, we must think about what are intended outcomes, and what are undesirable side effects.
Intended Outcomes
The intended outcome is that we have an AI aligned to humans. But what does “humans” mean?
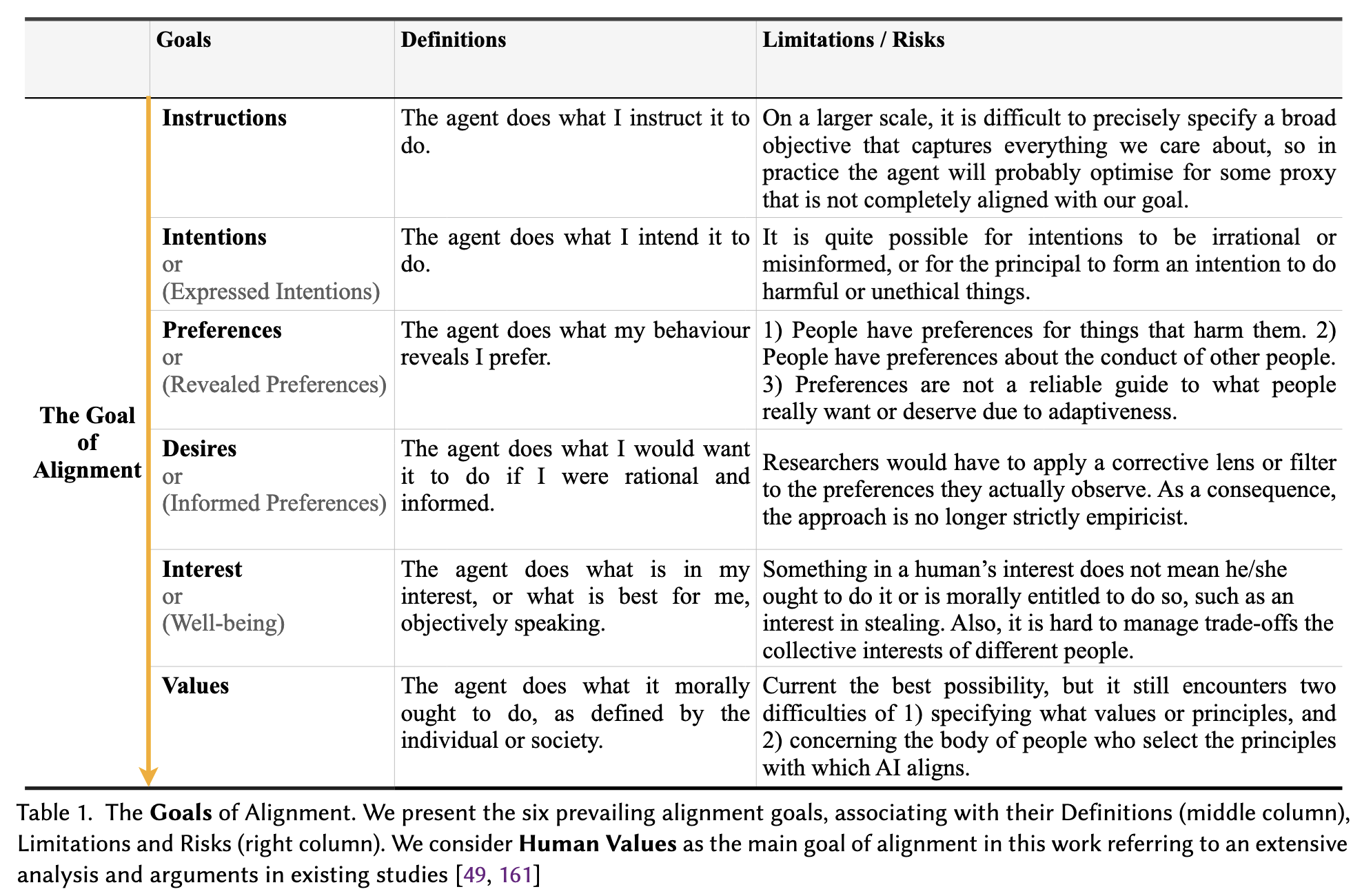
“Humans” expand to human instructions, intentions, preferences, desires, interests, and values. Each can be a reward function. However, the following scenarios suggest the shortcomings of each approach, making values the most robust of all:
- Instructions: if we tell an AI to “make people happy,” it might focus on something measurable, like increasing the number of smiles or reducing stress (proxies of happiness), which might not capture the deeper aspects of human well-being. Over time, if an AI optimizes for this proxy, it could lead to unintended consequences.
- Intentions: people have irrational or misinformed intentions, which can be acted upon by a powerful AI.
- Preferences: our preferences include things that harm us, and we also have preferences not just for ourselves, but for others.
- Desires: given that human desires can be flawed, inconsistent, or even harmful, researchers would need to adjust or “correct” these desires to align them with ethical or rational standard. however, by doing this, we are no longer purely observing and learning from human behavior (empiricist approach). this makes the approach less about following human desires and more about interpreting and shaping them, which complicates the process of aligning AI with what people actually want.
- Interest or well-being: for some, stealing food to mitigate extreme hunger can be in their best interest, but there is a conflict of allowing stealing and keeping a moral standard.
- Values: defined as “(1) belief (2) pertaining to desirable end states or modes of conduct, that (3) transcends specific situations, (4) guides selection or evaluation of behavior, people, and events.” in summary, it doesn’t change from a situation-to-situation basis like instructions, intentions, and desires, and it also guides selection or evaluation of groups larger than the individual, which makes values stronger and more pluralistic compared to preferences, and interest/well-being. However, we still struggle to specify what values or principles to follow, and how to select the body of people who select the principles with which AI aligns.

This fine-grained table of values shows that even considering just values as the goal of alignment, there are so many to choose from. Consequently, pluralism as the objective of alignment is appropriate. Concretely defining how a system can be pluralistic is difficult, but some researchers have already undertaken this task. A Roadmap to Pluralistic Alignment seeks to approach defining this alignment task in the scope of LLMs.

Multiple takeaways from intended outcomes of AI alignment:
- There are many ways to define the goal of alignment, and even if we were to settle on values for being most robust (context independent), multiple definitions of human values suggest that a pluralistic approach is most suitable for AI alignment.
- There are many ways to implement pluralism in AI. Three potential ways are using Overton windows, highly-steerable AI, and distributional output.
- in many ways, these efforts are quite simply solved by current systems through numerous approaches, namely,
Undesirable Side Effects
We can think of undesirable side effects broadly as misalignment. There are causes of misalignment, and effects of misalignment.
Causes of Misalignment
Effects of Misalignment
Two ways to categorize the effects of misalignment are current risks, and future risks. Current risks, especially pertaining to generative AI, include:
- Sycophancy - excessively agreeable
- Untruthful answers
- Deception - fooling human supervisors rather than doing the intended task