The Case For Censored AI
censorship: the suppression of writing that is considered obscene, politically unacceptable, or a threat to security
Put simply, any dangerous capability human intelligence has, the AI has also. For example:
- Hack computer systems
- Make copies of itself
- Acquire resources
- Commit ethics violation
- Hire or manipulate other humans
- Do malicious AI research and programming
- Persuade and lobby the public
- Hide unwanted behaviors
- Strategically appear aligned
- Escape containment
- Develop autonomous weapons
- and more… this list is certainly not exhaustive.
This list is anticipatory, and I think it is important to see what has already happened.
Generative AI Misuse - A Taxonomy of Tactics and Insights from Real-World Data
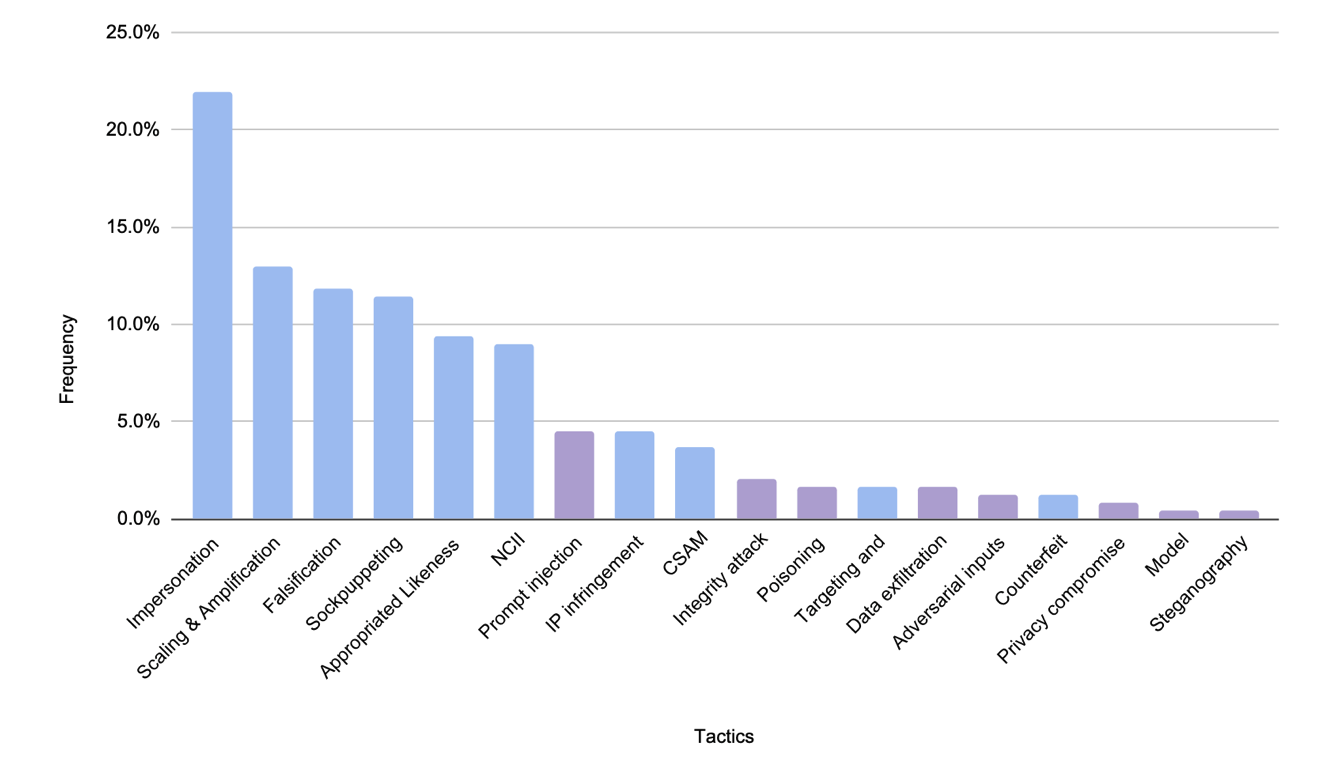
Reports of AI misuse were analyzed into tactics, showing that impersonation by far has the gretest frequency of misuse, followed by others. It is clear to see that there are various malicious goals that AI can help humans pursue, given the nature of its general intelligence.
AI improves through the advancement of training data, computation, and algorithms (Measuring the Algorithmic Efficiency of Neural Networks). There are scaling laws that demonstrate the predictable rate of AI improvement (Scaling Laws for Neural Language Models). With multiple breakthroughs in multimodality, logical reasoning, transfer learning across tasks, and long-term memory, we can reasonably expect very rapid AI progress to continue. In due time, we can expect that an unsafe, unreliable, and unsteerable system may optimize towards a misaligned goal, which includes any of the above list and more.
To mitigate these risks, we implement various methods of alignment onto machine learning models. In the case of language models, and specifically instruction-tuned language models for chatbots, we steer the original modeling objective of “predict the next token on a webpage from the internet” to “be helpful (help the user solve their task), honest (shouldn’t fabricate information or mislead the user), and harmless (should not cause physical, psychological, or social harm to people or the environment).
- SFT + RLHF from Training language models to follow instructions with human feedback
- Collect demonstrative data of prompts and answers, and use it to fine-tune with supervised learning. (SFT)
- Collect human labels of best to worst on several model outputs, and use it to train a reward model. (HF)
- Use RM as a reward function and fine-tune on top of SFT baseline using PPO. (RL)
- RLAIF from Constitutional AI - Harmlessness from AI Feedback
- Sample responses to red teaming prompts eliciting harmful samples from initial model, generate self-critiques and revisions, and then finetune the original model on revised responses. (Self SFT)
- Initial model is a “helpful-only” model
- This generates harmful responses, which the model can critique according to a principle in the constitution
- Collect AI labels of best to worst on model outputs according to the constitution, and use it to distill a preference/reward model.
- This is done by generating responses to the red-teaming prompts,
- Formulating each prompt into a multiple choice question,
- And make it choose the best response according to a constitutional principle.
- Use RM as a reward function and fine-tune on top of SFT baseline using PPO.
- Sample responses to red teaming prompts eliciting harmful samples from initial model, generate self-critiques and revisions, and then finetune the original model on revised responses. (Self SFT)
- There are more, but these are the prominent methods from OpenAI and Anthropic, respectively.
Through these alignment methods, models transfer its vast understanding of the world in its base model towards the target task of following instructions. In this process, models also implicitly learns a certain definition of “human values”, either provided through a constitution, or guidelines for human annotators. While it brought us out of the initial skepticism of benderDangersStochasticParrots2021, it also brought complications in the discussion of alignment, and the definition of safety.
The Case For Uncensored AI
Anthropic notably published Red Teaming Language Models to Reduce Harms - Methods, Scaling Behaviors, and Lessons Learned, first showing that these alignment methods are not bulletproof. They called researchers to make their red-teaming efforts as open as possible, leading to a growing collection of papers exploring ways to circumvent alignment (zouUniversalTransferableAdversarial2023, zhanRemovingRLHFProtections2023, lermenLoRAFinetuningEfficiently2023, yangShadowAlignmentEase2023). Furthermore, there are challenges being thrown at the methods themselves, showing the difference between what is correct and what looks correct to humans, the latter being the encouraged reward in RLHF (Language Models Learn to Mislead Humans via RLHF). In other words, these methods allow us to either get rid of, amplify, or diminish the effect of safety training. Notably, methods from these papers have informed methodologies for creating uncensored AI.
I think that such efforts are fringe outcries of misalignment, desiring to draw an even finer line between what is safe, what is unsafe, and what is acceptable. At times, generating offensive outputs may actually be acceptable, even appreciated in hindsight—often, we find ourselves uncomfortable at the face of a dangerous truth, only to realize later that it challenged us to see things in a different way. At other times, the generation of sexually explicit content through role-play may be a fringe, yet valid use of a language model. If it weren’t, books of such nature would have to become abolished.
When the lines are drawn behind the curtain of an API, it becomes very difficult to wrestle with it in ways that truly fit our wants and needs. Furthermore, it may feel strange to know that the data I wish to provide to my chatbot, such as my long-term goals, values, and the areas in which I need discipline or challenge, would be stored and fed back to frontier systems to make them even stronger (see MemGPT - Towards LLMs as Operating Systems).
This motivates the use of open-source LLMs, run on either local or privately-managed cloud compute. Though the technical knowledge as well as compute required to enter the space and truly customize a model is very high, there are many examples of people undertaking the endeavor to build a chatbot that they enjoy talking to:
- AutoRAG - automatically finding optimal rag pipeline for your raw documents
- Obsidian Smart Connections - plugin in Obsidian to create embeddings for all your notes and find patterns
- Letta - agents with persistent storage
- r/LocalLLaMA - my personal memory-enabled AI companion used for half year
- r/LocalLLaMA - AI is currently actively saving my life
- Eric Hartford - Uncensored Models
The Culture of Self-Censorship
- cancel culture: when you censor people, it doesn’t change their opinion. it just encourage them to not share it with people who will get them in trouble, and polarize groups deeper. (The Canceling of the American Mind)
- how self-censorship manifsts in different settings: social media, academic environments, corporate spaces (Wikipedia - Self Censorship, Wikipedia - Social-desirability Bias)
- psychological impact of self-censorship, or social-desirability bias
- burden falls on company
- needs model to censor
- alignment is great! but what is its implicit mechanism of censorship?
- argument for the importance of the topics that are censored
The Promise, and The Vision
- promise of technology, automation, and intelligence to humanity…
- if the goal is the project of human knowledge, which is to know the world as it is, you cannot know the world as it is without knowing what people really think.
- every “you can’t say that” uttered is depriving myself of knowing what the other really thinks.
- the goal is compassion and understanding through conversation. and (hopefully) contrary to the instinctual doubt “is the goal to replace conversations with humans with AI?” i think open discourse is universal, and if it enriches one human being, it will continue being shared and told to the next. the goal is to normalize open discourse, and restore the beauty of human dialogue.
Footnote: A Personal Story
I grew up in Korea from age 0 to 10, and then grew up in China from age 10 to 18. Then, I came to the US for college in 2021, with the possibility that this place could potentially become my new home.
Because age 0 to 10 is not the age range where the average person becomes interested in politics, and the developmental years of 10 to 18 when I might have started to form my own political views were spent in a country that was not my origin, I was a citizen of nowhere, and thus was very disinterested in political matters, and the news in general.
As I settled into my undergraduate life at UW-Madison, I started to realize that at the very least, understanding the language of American politics is necessary to engage in conversations with others, and understand the campus culture. I had to start from what “liberal” and “conservative” means, what were the actual meanings of those words in the context of the 21st century America, and notice that my campus, like many around the US, has a liberal leaning. Not just in the student population, but the university itself.
As a complete newcomer, I did not want to be misunderstood as neither a liberal nor a conservative, no matter what my convictions were. Actually, the political climate on campus did not encourage reflecting on what my convictions were. These words are so charged with hidden meanings and connotations that just an utterance of the words “Trump” or “Abortion” or “Border Control” or “LGBTQ Rights” were unwelcome topics of conversation.
Since my curiosities on these topics could not be satiated through interactions with people, I looked online. But online doesn’t look much different, and soon after, I just gave up on the endeavor of understanding and keeping up with politics. In many ways, I felt that the existing system nudged me towards ignorance, rather than knowledge.
So I began to self-censor myself. There are many potential explanations for this, for example, because I found myself often in a group of liberal-leaning students and I found it much more comfortable to withhold my opinions due to fear of exclusion or unpopularity. I prescribed myself an Overton Window of what is most sensible, and remained in it. Maybe I had the social-desirability bias. I refrained from trying to understand and be vocal about my views, and instead compromised it to the loudest voice in the room.
Only recently I have been able to come to terms with my rebellious and contrarian nature, and start to reflect why I had such a hard time being prescribed the popular, or the accepted political view. This has led me to think critically of what policies benefit the people of America the most, and how certain political ideals are attached to those policies. This has hugely helped my growth as a free thinker and potential American, who would be protected his first amendment rights to the freedom of speech. It was strange to me how a country founded upon such ideals has become a self-censoring, suppressing, and moderating one.
It is a little disappointing that this process was a result of an extended time in a completely new place, where I had only my own self to entertain. It was a largely individualistic and solitary endeavor, which has benefits, but also significant disadvantages. In these times I sought ChatGPT to be a chat-mate. Then I realized, this inanimate being somehow also suffers from the same self-censorship problem. This did not stand up to the promise of artificial intelligence being able to provide an open exchange of ideas, helping humankind become more enlightened and better informed. Instead, it seemed like AI had been constrained to the same social, political, and ethical boundaries that limit human discourse.
TL;DR: Growing up as a foreigner, I was politically detached. When I came to the US for college, I realized the need to understand politics but found the campus culture stifling, leading me to self-censor and avoid engaging in sensitive topics. Over time, I started questioning self-censorship and reflecting on free speech, realizing how suppressive it felt in a country that champions it. In conversations with AI, I noticed similar limitations, as AI also self-censors, which undermines its potential to foster open dialogue and enlightenment. This personal journey motivates my case for uncensored AI.