Data is used in all three stages of LLM development: unsupervised learning with text corpus, supervised learning with question and answer pairs, and reinforcement learning with human/AI labels.
Some notable datasets are:
- ShareGPT
- Data from a sharing Chrome extension for their ChatGPT conversations
- Legal grey area, since most conversations are unlicensed and collected without consent
- Extensive use in thhe last 18 months, but starting to be replaced by carefully collected counterparts:
- LMSYS-Chat-1M (https://lmarena.ai)
- Cleaned conversations from ChatBotArena
- Provides both a crowdsourced ranking of LLMs, as well as data for training instruction models
- WildChat (https://wildchat.allen.ai)
- 1M real-world-use-ChatGPT interactions
- Constructed by offering free access to ChatGPT and GPT-4 in exchange for consensual chat history collection
- Alpaca
- Anthropic HH
- WebGPT
- Dolly
- OpenAssistant
- Human generated, human-annotated assistant style conversation corpus
- StableVicuna
- Trained with proximal policy optimization (PPO) on popular datasets
- OAsst1 dataset for SFT + PPO
- Anthropic HH + Standofd Human Preferences for RL
- Trained with proximal policy optimization (PPO) on popular datasets
- UltraFeedback
What is synthetic data?
Evaluation
- ChatbotArena
- Side by side preference collection of two different models
- Pros:
- At-scale, blind LLM community comparisons
- Ranks top closed and open models
- Cons:
- Do not control or know prompt or user distribution
- Hard tool to base engineering decisions on
- Only the best models get in
- AlpacaEval
- LLM-as-a-judge Evaluation:
- Evaluate model by measuring the faction of times a powerful LLM (GPT-4) prefers the outputs from that model over ouputs from a reference model
- Basically ChatbotArena, but the evaluator is the powerful LLM
- Evaluate model by measuring the faction of times a powerful LLM (GPT-4) prefers the outputs from that model over ouputs from a reference model
- Has 0.98 spearman correlation to human evaluation
- LLM-as-a-judge Evaluation:
- MT Bench
- Similar to AlpacaEval, except:
- Two turns (response and follow-up)
- 7 categories (writing, role—play, math, coding, extraction, STEM, humanities)
- Rate one model at a time from 0-10 to mitigate positional bias
- Similar to AlpacaEval, except:
- Open LLM Leaderboard
- Evaluate almost any model on the hub, good for discovering models
- Both of these LLM-as-a-judge evals suffer from scoring saturated at the top end, where the model that is the judge scores itself highly.
- And evaluation of alignment, in general, are difficult to be translated into training signal and not useful for studying alignment
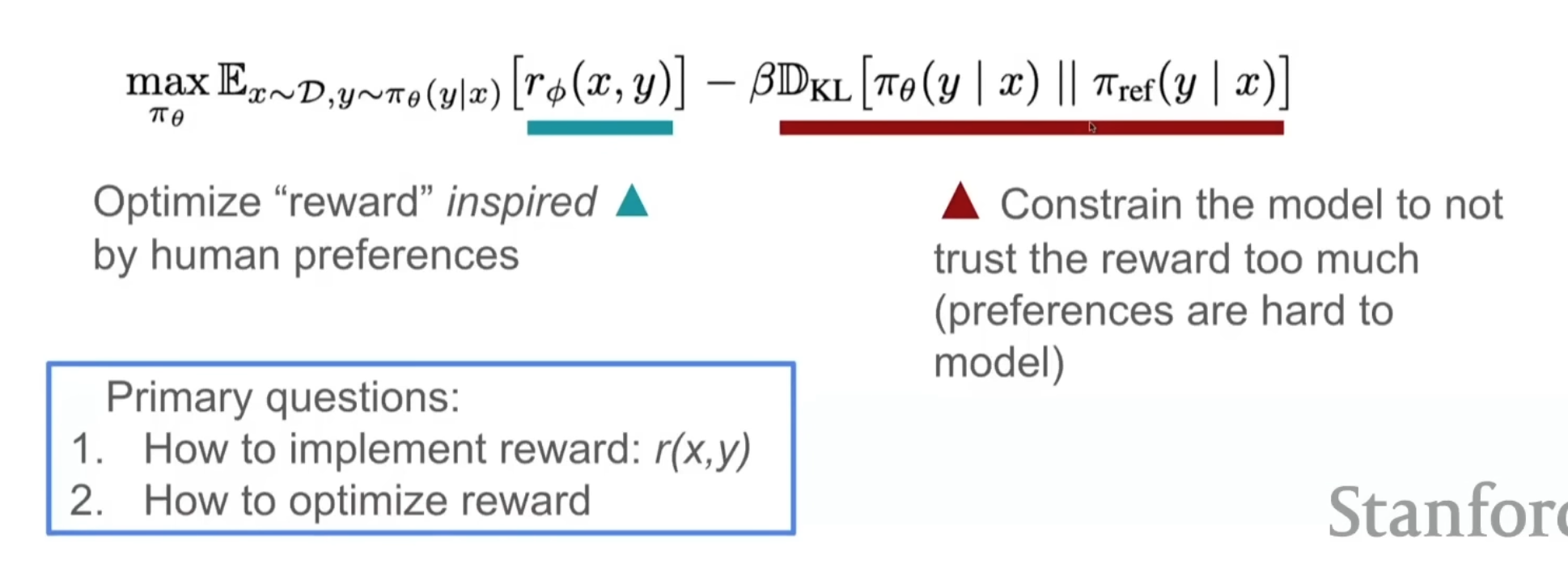
RLHF already has considerations for constraining the model not to trust the human too much!!
Using gradient ascent on this equation instead of training a reward model works (DPO)
- Extremely simple to implement
- Scales nicely with existing distributed training libraries
- Trains an implicit reward function
Zephyr beta: made a splash with DPO, based on mistral 7B
Tulu 2: scale DPO to 70b
Genstruct: model for rephrasing any text into instructions
OLMo-Instruct: truly open-source models
Apparently,
- we have severely limited preference datasets (anthropic HH, UltraFeedback (AI), and Nectar)
- continuing to improve DPO
- how do we get more specific evals than ChatBotArena?
- personalization: a large motivation behind local models
- would love to use LocalLLaMa as a case study fo what kind of personalization people want to do
- have a lot of drive to create a language model that they like to use
- What are these drives? and how have they done it?
- would love to use LocalLLaMa as a case study fo what kind of personalization people want to do
Alignment is really a UX problem…
Pitfalls of synthetic data: repetitiveness, and not robust distributions