This is one of the early era of posts within r/LocalLLaMA, date 2023-05-03. It is an attempt to combine the best of two approaches to instruction tuning at the time, and perhaps this can be slightly over-interpreted that people had the ability to experiment and do meaningful innovation on models to a greater degree than they do now.
They share three artifacts—the GitHub repo that contains documentation, the dataset, and the model that was fine-tuned on the dataset. They use a mixture of the WizardLM technique of extending a problem by taking a single instruction and blowing it up into a long, detailed chain of sub-problems, and it uses the Vicuna-style conversational format and training techniques. It resulted in a 7% performance improvement over VicunaLM using data generated by WizardLM (transfer learning?).
Because of the promising results, people ask for application of the project’s idea to different models.
This updated set of logs are interesting in this instance:
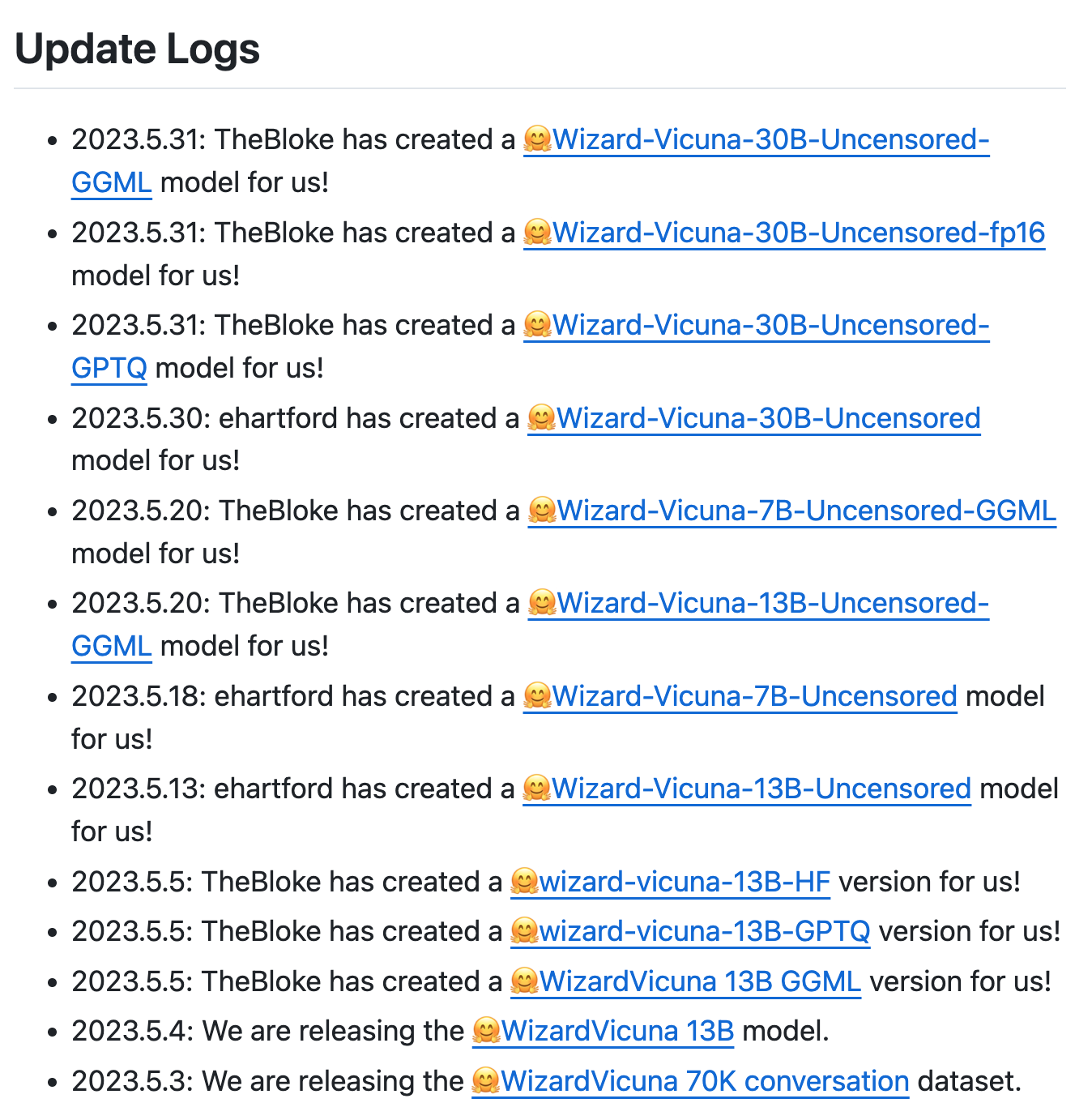
Note that the models coming after the OP’s release are all applications of the same technique to smaller and larger models, as well as in different model formats. Perhaps this isn’t “collaboration”, but when one person has a good idea, others who have the compute “complete the job” by applying it to other models that people have demand for.