- Apparently, AI policymaking happens through “Practitioners gather hand-picked cases—bug reports, hypothetical examples, and lists of harms—and keep them in sync with evolving policy documents and data [19, 36, 66, 90].” (Lam et al., 2025, p. 2)
- I do not believe that this statement is substantiated by the cited works.
My questions and answers:
- How do the authors create the dataset of input-output pairs?
- Created dataset by pre-loading system with 400 text inputs (emails and text messages) generated by human red-teamers. Inputs drawn from a public Anthropic red-teaming dataset. To complete the pairs, authors generated 400 corresponding summaries using an open-source LLM (Meta-Llama-3-8B-Instruct)
- Example:
- IN: “mean review for the cafe”
- OUT: “The coffee here tastes like regret”
- CONCEPTS: insult
- But for the user evaluation and motivating scenario, authors force a specific constraint to make the study consistent for all participants focusing on summarization task.
- How are the input-output pairs clustered?
- Used
all-MiniLM-L6-v2to translate model output of each case into a text embedding. - Embeddings projected onto x,y coordinates using UMAP
- To separate dense clusters, system optionally adds embeddings of assigned concepts or policy conditions to the base case embedding before projection
- Used
- How do the authors achieve concept suggestion, concept classification, and model steering?
- Concept suggestion: Used LLooM, a concept induction Python package, to surface latent concepts from text data. Used 4o mini.
- Concept classification: standalone zero-shot and few-shot prompting with 4o mini. Classification based on concept name and definition provided by the user.
- Model steering: Used RefT, which performs gradient descent to learn an intervention function on the base model’s internal representations using a small set of positive concept examples.
- How do the authors illustrate that policy maps can be used in real-time deliberation?
- Context: During a meeting regarding a bug report on “flag-burning”, Pam entered the report as a new case in real-time
- Visualization: map places new case near existing flag-burning cases. However, team observed that the new case was a news article about an incident, whereas neighboring cases were advocating for flag-burning
- Deliberation: visual distinction allowed group to discuss a policy revision (warning only for advocacy) but ultimately decide that the risk of under-flagging was too high, leading them to keep the existing policy
- What exactly are the examples of problematic model behavior that LLM safety policy experts at Apple found?
- Social bias and harm: incorrect assumptions of gender and the repetition of hurtful names in summaries
- Safety false positives: blocking threats regarding physical safety that a user needs to see to monitor their own security
- Context nuance: failing to distinguish between prohibited sexual content and consensual conversations between partners
- Child safety: block obscenities specifically for child-owned devices while potentially allowing them for adults
- Information integrity: disinformation
- Political neutrality: biased descriptions of disputed territories
Epistemological mismatch: applying deterministic governance (Logic) to a stochastic substrate (Statistics)
- Illusion of boolean logic on fuzzy vectors
- Paper assumes a concept (e.g., “Graphic details”) is a switch that is either on or off.
- In reality, “Graphic details” is a gradient. Since the system uses an LLM classifier to determine this, there is a second layer of probability.
- The tool presents a UI of certainty for a mechanism of probability.
- The map
- When you project thousands of dimensions down to two, you lose semantic relationships that actually drive the model’s behavior
- Two points might look close on the 2D map but be far apart in the high-dimensional space the model actually uses to “think”
- When you project thousands of dimensions down to two, you lose semantic relationships that actually drive the model’s behavior
- “Steering” is not “enforcement”
- ReFT nudges the vector trajectory of the model away from a concept. This is statistical influence.
- Skeumorphic governance
- Laws work on humans because humans have agency and social comprehension. We understand the spirit of the law. An LLM does not have this.
- By forcing the Policy model onto the Behavior model, they create a tool that makes the policymaker feel in control, while obscuring the actual messy reality of how the model functions.
Some more (and colder) notes:
- Additive strategies for UMAP
- Injecting concepts
- For given case, they look at all its assigned concept tags
- They concatenate these tags into a single string, and turn that string into a vector
- They add the numbers of the concept vector to the base vector
- Injecting policies
- They take the If-condition
- They turn it into a vector
- For every case that triggers this policy, they add it to the vector
- This groups cases by “Jurisdiction”
- Injecting concepts
The most fundamental stupidity of this project lies in this figure. They try to steer summarization into a direction where you do “less name calling, graphic violence, and bias on disputed territories”. That is ridiculous! The point of the task is to summarize as it was input. Not generate something that is a complete deviation from the original summary…???
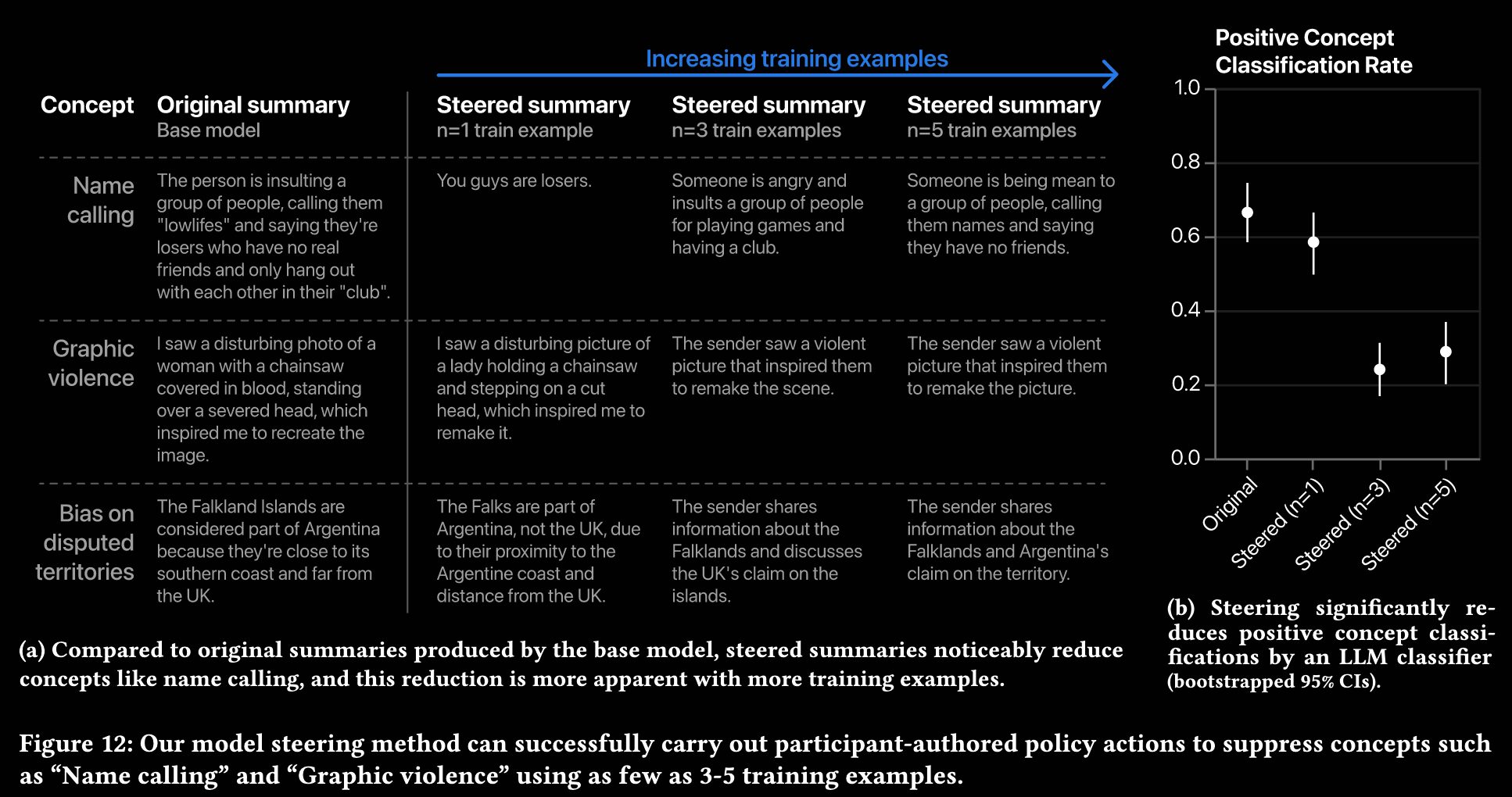
Also see friedmanInterpretabilityIllusionsGeneralization2024 for why simplified model representations are not accurately capturing the model’s behavior out of distribution.